Building Software for its Native Habitat
Throughout my time working on many product lifecycles I have noticed there seemed to be an inevitable disconnect between greenfields work and production support. There is a gap between developing software and the mindset of maintaining it over a long period of time. Closing this gap is central to microservices thinking.
DevOps First Approach to Microservices
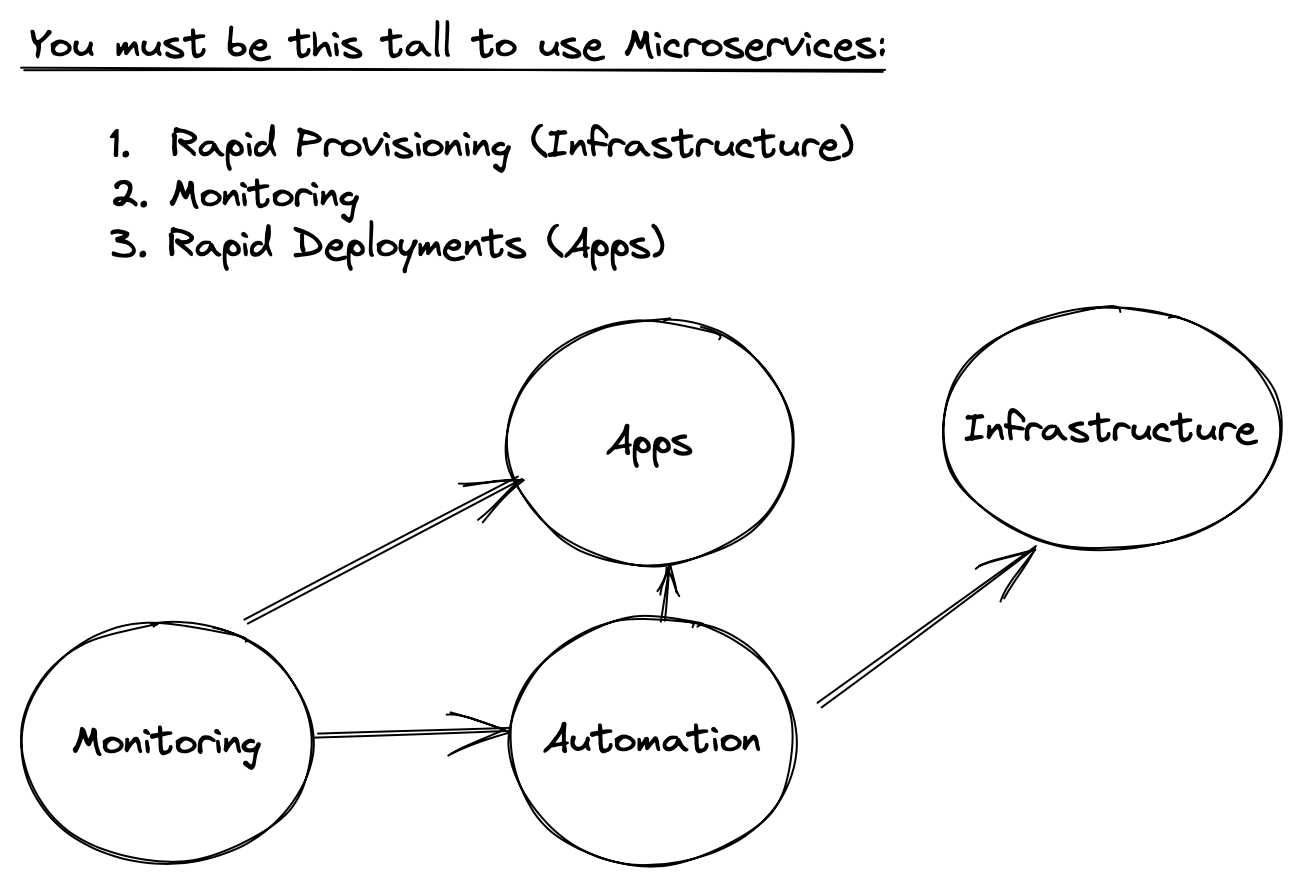
The disconnect between build and maintain, both from an operational and time-to-deliver perspective is central DevOps. Martin Fowler outlined the "Microservices Prequisites" as a set of DevOps practices that shorten the distance between monitoring, deployment cycles and infrastructure provisioning.
Cloud Native Apps and Architecting for Reliability
Once these foundations in place we can begin thinking about designing software in a way that plays well with CI/CD and automated infrastructure.

The 12 factor app outlines a way of building software that focuses on predictable behavior when deployed frequently to an elastic environment. The factors 1-5 focus on how an artefact is structured for a deployment pipeline. Factors 6-12 focus largely on the approach to designing software to function predictably within an elastic infrastructure. The notion of process isolation forms a common theme across the factors.
For example, in factor 1 - we lose isolation if we are deploying multiple applications from a single code repository.
Similarly in factor 2 - managing dependencies such as libraries and runtimes in isolation is also important. Each deployment of an app should be independent and not rely on the target environment for consistency. Package managers such as npm are an example of managing application dependencies in a declarative and self contained way. Containers extend this idea where you can have a consistent runtime per deployment.
In order monitor an application and scale accordingly, some form of supervision must be done. The twelve-factor app offloads the responsibility of supervision to the underlying platform, and mandates that the app be designed to play well with this arrangement. The idea here is to keep applications lightweight, stateless and disposable, while allowing the infrastructure to provide reliability and consistency across running processes.
Similarly log aggregation and web server integration are not application level concerns. Logs are written to sdout and transparent as an output stream to the application. Communication is handled via port binding.
Infrastructure for Site Reliability
By moving towards a more distributed and stateless software paradigm, some application level concerns move towards the platform level. In return for this we have applications that are easier to reason about in terms of their long-term behaviour when encountering faults or issues in production.
When the infrastructure takes up the slack of these lightweight processes, we usually need some of the following components and concepts to support this:
- Key value stores such as Redis for offloading any requirements for persistent local state.
- Supervision of processes. This includes responsibilities at the platform level for autoscaling, recovery and health checks.
- Supervision of communication. Load balancing, timeouts, circuit breakers and failover when resources become unavailable.
- Log aggregation frameworks for managing log streams.
Coding for Site Reliability
Software can be designed to have some responsibility over platform and infrastructure level concerns. For example to avoid resource bottlenecks that can cause cascading failures, some of the approaches might be used at the application level:
- Embracing event driven design where possible to reduce the need for blocking calls on backing services. This means any failed process can also pick up on where they left off after being respawned.
- Timeouts and exception handling, as well as the use of circuit breakers when event driven design is not an option.
- Using a lightweight concurrency framework at the application level to improve the resource utilisation of the underlying platform.
- Admin processes are first class citizens and should be developed up front to manage these extra moving parts, such as clearing out temporary data stores and managing un-processed messages.